Gc, C, Algorithm
Tri-Color Garbage Collector
Garbage collectors (GCs) feel like some sort of esoteric programming magic. What’s really funny is that a simple good-enough garbage collector is actually quite easy to write. The core functionality of a basic tri-color GC is only around 250 lines of C code.
The only real hard part about writing a GC is to build the confidence that – yes – you are capable of writing one! Really: this isn’t black magic. If you can write C code, and you understand pointers and basic bit manipulation, then you’re perfectly capable of understanding and writing GCs.
I researched a couple different GC algorithms, and settled on a basic tri-color mark-sweep for this experiment. I insisted that the GC be incremental so that I could use it in game engines if I wanted – I didn’t want to have long pauses while the GC was running, which would affect frame rate.
Allocation
You would think Garbage Collectors are about collecting garbage. That’s only half of the equation though. The GC begins at allocation.
When you design a garbage collector, you are first designing an allocater.
Tables
Allocation is pretty simple: I preallocate a large table of each type. For example, I have a string table, a list table, a hash table, etc.
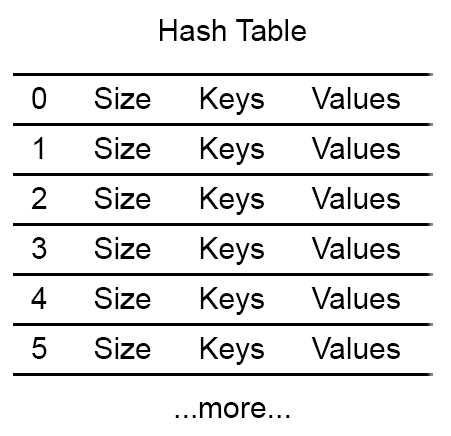
Basic Hash Table
For the hash table, each slot in the table contains a size, a pointer to the list of keys, and a
pointer to the list of values. The pointers are NULL when the slot is unallocated.
Bitmaps
Next, I use a bitmap to track whether a slot is allocated or not.
Basically a bitmap is a list of 64-bit unsigned integers. That means for each integer in the bitmap, I can track 64 slots in my table. For this reason, I preallocate the tables in multiples of 64 slots, so that every bit in the bitmap is used.
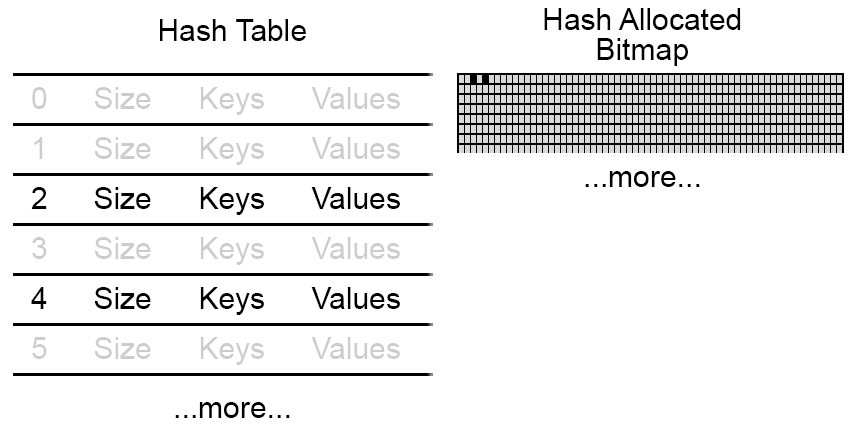
Allocation Bitmap
If a bit is 1, then the corresponding slot is allocated – otherwise, the slot is free to use.
Allocation Algorithm
At this point, it’s pretty obvious how allocation would work: if we need a new hash, then scan the
allocation bitmap for a 0. The first 0 we find will give us the slot to use.
Then, set the bit to 1 to indicate that the slot is now allocated, and return the slot.
The only trick here is to scan the allocation bitmap quickly: we can check 64 slots at a time by
just seeing if the allocation integer is 0xFFFFFFFFFFFFFFFFLL (64-bit unsigned int with all bits
set).
Once we find a non-full integer, then find the first bit inside the integer that is a 0. Turns
out the C function ffsll finds the first 1
pretty damn quickly, so we just need to bit-not (~), and search for 1.
(ffsll also starts counting at 1, but we want to start counting at 0, so we subtract 1)
Here’s the allocation code:
int64_t bmp_alloc(uint64_t *bmp, int64_t slots){
// search for the first 0 bit, set it to 1,
// then return the slot
// return -1 if nothing found
slots /= 64; // checking 64 slots at a time
for (int64_t loop = 0; loop < slots; loop++){
if (*bmp == 0xFFFFFFFFFFFFFFFFLL){
// this area is full, go to the next area
bmp++;
continue;
}
// we're guaranteed at least one bit is 0
int pos = ffsll(~*bmp) - 1;
*bmp |= 1LL << pos; // set the bit at pos
return loop * 64 + pos;
}
return -1;
}
Hopefully that isn’t too scary for you. It’s just what I’ve described.
The only thing left is when bmp_alloc returns -1, that means our table is completely full, so we
need to grow our table and bitmap. That’s just a matter of realloc and memset.
And that’s it for allocation! See, writing your own allocater isn’t that hard 😀.
Mark/Sweep
Now we get to the core algorithm.
Mark/sweep is dead simple – our goal is to traverse all the values to see what is reachable from the machine. After we’re done traversing, whatever is allocated but unreachable needs to be deallocated.
So if you think about it, this is what we need:
- A way to mark that we’ve visited a value
- A way to crack open a value and visit everything inside
- A starting point
The basic algorithm will be:
Phase 1: Start
- Clear the mark on all values, everywhere
- Create a list of values that need to be processed (the “pending” list)
- Add the starting values to the pending list, marking them
- Go to phase 2
Phase 2: Mark
- Pull a value off the pending list
- Crack it open and traverse all the values inside of it
- For each child value, if it is already marked, ignore it; if it isn’t marked, mark it, and add it to the pending list
- Keep pulling values off the pending list and processing them until the list is empty – then go to phase 3
Phase 3: Sweep
- For every allocated value, check to see if it’s marked
- If a value isn’t marked, then free any memory associated with the object, and clear the allocation bit of its slot, so it can be reused
- Go back to phase 1
Make sure this makes sense!
The final code won’t look exactly like this, but this is the essence of the algorithm. Convince yourself that this algorithm works.
It’s important to truly and deeply understand this core algorithm, because later we’re going to have to figure out how to make this incremental without screwing it up.
Referenced Bitmap
So, it looks like we’ll need a way to mark each value. Let’s use another bitmap.
For each table, in addition to the allocation bitmap, we’ll have a referenced bitmap. The
referenced bitmap will have a 1 if the value is marked, indicating that it is reachable from the
starting point.
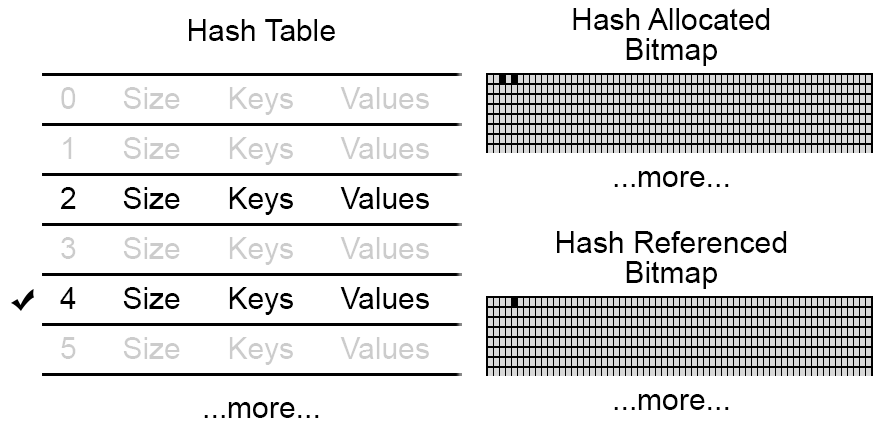
Referenced Bitmap
This might seem a bit weird to use these bitmaps – why not just put an allocation bool and a referenced bool inside of each slot in the table?
Speed, of course.
Remember that our allocation algorithm could check 64 slots at a time – it didn’t have to run down each slot and look at each individual bool. We’ll see more bit tricks that will speed up deallocation later.
Starting Point
Where do you start? That depends on your VM.
This experimental VM is a register based machine. That means I have instructions like
R3 = StrCat R2, R0, which says “create a new string by concatenating the strings in register 2 and
register 0, and store the result in register 3”.
The key insight is that the registers alone work as a starting point.
Why is that?
The only way to reach an object is if the object is in one of the registers, or if you can traverse to the object using what’s already in the registers.
So, if we use the registers as our starting point, our Mark phase will do the same traversal as any possible instruction sequence, which guarantees that we won’t accidentally deallocate something our VM could use.
Adding to the Pending List
One more thing…
We’ll be adding a lot of things to the pending list, in a lot of different scenarios, so it’s best to think about solving the general case.
Suppose you are simply given a list of values. How would you determine if they should be added to the pending list?
The value’s type must be checked, and categorized into three basic buckets:
Non-allocated Values
If the value is void, null, boolean, or a number, then it’s skipped entirely: the GC doesn’t
operate on these values, because they aren’t allocated in the first place.
Allocated but Non-traversable
If the value can’t be traversed, then it’s marked, but it isn’t put on the pending list. Why put something on the pending list if it doesn’t have any child values? Think of a string: yes, it’s allocated, but you can’t crack it open and find more values inside of it.
Allocated and Traversable
Lastly, we have values that are allocated and can be traversed – these are things like lists and hashes.
If the value is already marked, then we ignore it. That’s because if it’s marked, that means it’s already been processed, so we don’t want to process it all over again.
Otherwise, finally, at this point, we mark the value, and add it to the pending list. This is the only situation where a value is added to the pending list.
Code
Here is a basic implementation. I call the function gc_add_gray because in traditional GC
terminology, adding something to the pending list is “coloring it gray”. Silly, I know, but we’re
stuck with it.
void gc_add_gray(uint32_t size, value *vals){
if (size == 0)
return;
uint32_t size_filtered = 0;
value *vals_filtered = malloc(sizeof(value) * size);
value v;
uint64_t *ref_bmp;
uint32_t slot;
for (int64_t i = 0; i < size; i++){
v = vals[i];
switch (value_type(v)){
case VALUE_TYPE_NUM:
// skip unallocated values
continue;
case VALUE_TYPE_STR:
// just set the referenced bmp's bit at
// the slot and move on
slot = value_slot(v);
bmp_setbit(str_referenced_bmp, slot);
continue;
case VALUE_TYPE_HASH:
ref_bmp = hash_referenced_bmp;
break;
// ...more types...
}
slot = value_slot(v);
// if it's already referenced, then skip it
if (bmp_hasbit(ref_bmp, slot))
continue;
// otherwise, mark it and add it to pending
bmp_setbit(ref_bmp, slot);
vals_filtered[size_filtered] = v;
size_filtered++;
}
// actually add the filtered values to the
// pending list
gc_add_pending(size_filtered, vals_filtered);
free(vals_filtered);
}
Phase 1: Start
Now, it should be obvious how to implement Phase 1.
Clearing the mark for all values is easy, just memset the entire referenced bitmap to 0 for each
table.
Creating the pending list is easy… something like this:
int pending_list_size = 0;
int pending_list_total = 256;
value *pending_list =
malloc(sizeof(value) * pending_list_total);
This is your basic variable length list implementation in C. Nothing new here.
(In practice, the pending list is only created once, and we just empty it here by setting
pending_list_size to 0)
Adding the registers is cake too!
Something like: gc_add_gray(registers_size, registers);
Phase 2: Mark
This is now pretty simple because we’re guaranteed only traversable values end up on the pending
list, and gc_add_gray does all the heavy lifting.
So grab the next value, check its type, and gc_add_gray its children.
if (pending_list_size == 0)
goto sweep;
pending_list_size--;
value v = pending_list[pending_list_size];
switch (value_type(v)){
case VALUE_TYPE_HASH:;
value_hash h = value_to_hash(v);
gc_add_gray(h->size, h->keys);
gc_add_gray(h->size, h->values);
return;
// ... more types ...
}
Phase 3: Sweep
Now for the fun part!
At this point, we’ve traversed everything, starting from the registers, and marked the referenced bitmap of everything we could reach.
Now we need to compare the referenced bitmap to the allocated bitmap. If something is allocated but not referenced, then we need to free it.
Here’s how it would work for the hash table:
int64_t slot;
int bit;
for (int64_t i = 0; i < hash_slots / 64; i++){
uint64_t free_bmp =
hash_allocated_bmp[i] &
~hash_referenced_bmp[i];
hash_allocated_bmp[i] ^= free_bmp;
while (free_bmp != 0){
bit = ffsll(free_bmp) - 1;
slot = i * 64 + bit;
free(hash_table[slot].keys);
free(hash_table[slot].vals);
free_bmp ^= 1LL << bit;
}
}
So this might take a little bit of explaining.
Calculating Who Gets Freed
First, we look across all hashes in the table, but we look 64 at a time.
We need to calculate which slots need to be freed. Let’s do this using a small example. Suppose we were looking 8 at a time, instead of 64 at a time, and our bitmaps have the values:
allocated_bmp = 01001101
referenced_bmp = 00001001
We want to mask out the referenced bits. So, if we bit-not (~) the referenced_bmp, we get:
~referenced_bmp = 11110110
Then if we bit-and (&) it with the allocated_bmp, we get:
allocated_bmp = 01001101
~referenced_bmp = 11110110
free_bmp = 01000100
Tada! Now free_bmp has the bits set of the slots we need to free.
Unallocating
Unallocating is a one liner: allocated_bmp ^= free_bmp;
How does this work?
Remember that ^ is the bit-xor operator. Basically, think of it as the bit toggler.
allocated_bmp = 01001101
free_bmp = 01000100
result = 00001001
Where free_bmp has a bit set, it flips the bit on allocated_bmp – unallocating it.
Freeing the Objects
Lastly, we need to free all the objects.
We have free_bmp, which has a bit set for each object we need to free. So, we loop around until
free_bmp is 0, grabbing the next 1 bit in free_bmp (using ffsll), calculating the slot
that the bit corresponds to, freeing the hash at that slot, and finally toggling free_bmp at that
bit.
It’s a mouthful, but hopefully it does make sense, at this point.
As a word of encouragement: don’t expect to be able to read C code quickly. I come from web development, and I can read tons of web code very quickly, because a lot of it is very generic. C code is very granular and specific – sometimes you have to take it one line at a time, and slowly figure it out. That’s okay.
Done! Sort of…
And there you have it! A complete stop-the-world garbage collector!
Er… well… actually, that’s not what we wanted.
We specifically wanted an incremental garbage collector.
An incremental garbage collector means that we can work on garbage collection interleaved with the regular execution of our VM, like a slow drip.
Even if it takes longer overall to clean the same amount of memory, it’s still much better to spread that work evenly over the entire execution of the VM, because we plan on using this for game development, and don’t want annoying pauses.
The good news is that we’re 95% there. Now we just have to think through what it would take to make this incremental, and make the necessary modifications.
Write Barrier
The difference between a stop-the-world GC and an incremental GC is a write barrier.
What is a write barrier, and why do we need it?
Let’s identify the problem.
See, we can actually make our GC incremental already. Our slow drip could simply be removing one element from the pending list, and processing it. We could easily interleave VM execution with the Mark phase. Nothing says we need to blast through the pending list all at once.
That takes literally zero modifications to the GC algorithm. Just slowly work off the pending list, and eventually we’ll get all the way through it.
This doesn’t work on its own though. Why not?
Because you can shuffle things around in such a way that a value misses being marked.
Here’s one example:
R0 = ['apple', 'banana']
R1 = void
Mark the registers
- Mark the list in R0, add to pending list
- Skip the value in R1, because it's void
R1 = ListPop R0
Process the next pending value
- Remove the list in R0 from the pending list
- Traverse all children
- Mark 'apple' ('banana' was popped, and isn't here!)
Process the next pending value
- Pending list is empty, so sweep
Free the string 'banana' because it wasn't marked
What happened? 😓
The 'banana' string skirted around the mark phase. It did this by hiding in a register that was
already scanned.
What is the answer?
Every time you write to a register, you have to rescan it with gc_add_gray.
Hence, write barrier.
The downside is obvious: gee, aren’t we writing to registers an awful lot? Yes, yes we are. But we can speed it up slightly by observing that we’re only interested in instructions that write allocated objects to registers, if that makes you feel any better.
For example, we don’t need a write barrier on R0 = NumAdd R1, R2, because numeric addition will
never write an allocated object to a register.
This write barrier can trip you up – for example, how do you deal with C extensions mucking with data?
Imagine a C extension that scans a list and replaces each element with a new string that is uppercase.
R0 = ['apple']
Mark the registers
- Mark the list in R0, add to pending list
Process the next pending value
- Remove the list in R0 from the pending list
- Traverse the children
- Mark 'apple'
UppercaseListExtension R0
Process the next pending value
- Pending list is empty, so sweep
Free the string 'APPLE' because it wasn't marked
Wait, what?!
The C extension did not pass their modifications through any registers, so the write barrier didn’t pick them up.
How I handled this particular case is that any new allocation is automatically marked as referenced, and any write to any container object (lists, hashes, etc) trips the write barrier.
Write barriers are expensive, but the point is to amortize the cost of memory management over the entire system.
Summary
Boy, for something I’m claiming is “simple” and “easy”, this is sure a long post!
Writing a garbage collector is easy in the same sense that digging a ditch is easy. Just because it’s easy doesn’t mean that it doesn’t take work: you just have to take it one step at a time.
Garbage collectors seem mystical from the outside… whatever you throw at it, they slowly chug away, and clean everything up. But these systems are no more complicated than any other system your average programmer would create.
You just have to be exposed to the ideas and take the time to work through them. You just have to dig that ditch.
Just like learning thread programming, or how compilers work, or regular expressions, or any other computer science topic, it only looks magical from the outside – from the inside, they are fun little creatures to play around with and make tick 😀. Don’t be scared.