Shunting Yard, Javascript
Shunting Yard (Part 2)
Let’s continue building a general purpose Shunting Yard algorithm.
We left off with bare-bones skeleton that implements a shunt to delay building of the abstract syntax tree (AST). Our skeleton left a lot to be desired. For this article, we’ll implement operator precedence.
Please read Part 1 first, since the code here builds directly on the source from that article.
Series: Part 1, Part 2, Part 3…
The Problem
What is operator precedence, anyways?
Consider the following expression:
20 + 30 * 40
Most people are so hard-wired to perform math, it can be hard to see what is happening here with the symbols. Let’s swap out some symbols, so we can view the example more abstractly:
<num1> FOO <num2> BAR <num3>
I’ve replaced all numbers with <numX>, the + with FOO, and the * with BAR.
The problem is: how do we build the AST? We have two options:
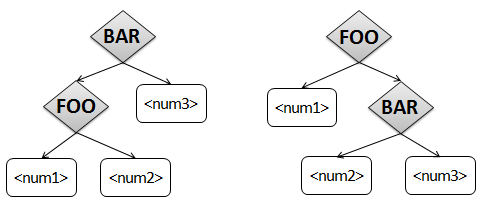
Apply FOO or BAR first?
It’s like FOO and BAR are competing for the <num2> value… who will win this competition?
We can easily apply FOO first – that’s what our code from last time did (always). What would it
look like to apply BAR first?
Stacked Shunt
Let’s go to the extreme. What would it look like if we always applied the right operator?
<num1> FOO <num2> BAR <num3> BAZ <num4> QUX <num5>
In order to apply FOO, we need to apply BAR first.
But in order to apply BAR, we need to apply BAZ first.
But in order to apply BAZ, we need to apply QUX first.
But that’s the end – so we apply QUX.
Then we can apply BAZ…
Then apply BAR…
Then FOO.
In our previous code sample, we had a variable lastOp that stored the last operator we parsed, so
that we could apply it after getting the following expression.
But now we need multiple lastOp variables… and we need to be able to unwind them. Looks like a
job for a stack!
Stacked Values
The next question is: when we apply QUX, how do we know what to apply it to?
In our first piece of code, we always had the left expression, and the right expression. The
left expression was inside the lastValue variable, and the right expression was in nextValue.
Which makes sense if we’re always applying the left operator first: the tree was always being
built on the left side. The lastValue variable stored the root of the tree.
But now we can have multiple roots. For example, in this expression:
2 * 3 + 4 / 5
We would build the tree like this:
(2 * 3) + (4 / 5)
The + has a tree to its left and right. The left is 2 * 3, and the right is 4 / 5.
Looks like we need another stack! This stack is for values, and represents the roots of the trees up until the expressions need to be combined by an operator.
The Code
Enough blather – let’s look at the code. It’s helpful to compare it to the first version, from the previous article.
function PrecedenceShuntingYard(tokens){
// helper function to get the next token and validate its type
var tokenIndex = 0;
function NextToken(requiredType){
if (tokenIndex >= tokens.length)
throw 'invalid expression: missing token';
var tok = tokens[tokenIndex];
tokenIndex++;
if (tok.type != requiredType)
throw 'invalid expression: expecting ' + requiredType;
return tok;
}
// helper function to apply a binary operator based on a symbol
function ApplyBinOp(symbol, left, right){
var sym_to_type = {
'+': 'add',
'-': 'sub',
'*': 'mul',
'/': 'div'
};
if (!sym_to_type[symbol])
throw 'invalid expression: unknown operator ' + symbol;
return {
type: sym_to_type[symbol],
parms: [left, right]
};
}
// determines if we should apply the left operator before the right
function ApplyLeftFirst(leftSymbol, rightSymbol){
var sym_to_prec = { // map symbol to precedence
'+': 0,
'-': 0,
'*': 1,
'/': 1
};
return sym_to_prec[leftSymbol] >= sym_to_prec[rightSymbol];
}
var tok, nextValue;
var opStack = [];
var valStack = [];
function ApplyTopOp(){
var op = opStack.shift();
var rightValue = valStack.shift();
var leftValue = valStack.shift();
valStack.unshift(ApplyBinOp(op, leftValue, rightValue));
}
while (1){
// grab a terminal (which is always type 'num', for now)
tok = NextToken('num');
// create the terminal node
nextValue = {
type: 'val',
value: tok.value
};
// save the value to be operated on
valStack.unshift(nextValue);
// if we're out of tokens, then exit
if (tokenIndex >= tokens.length)
break;
// otherwise, we must have a binary operator
// grab an operator (which is always type 'sym', for now)
tok = NextToken('sym');
// check to see if we have previous operations to apply
while (opStack.length > 0 && ApplyLeftFirst(opStack[0], tok.value))
ApplyTopOp();
// save the new operator to be applied later
opStack.unshift(tok.value);
}
// apply any left over operators
while (opStack.length > 0)
ApplyTopOp();
// all done, so return the top of the tree
return valStack[0];
}
It might look a little intimidating at first, but if you look closely, there were only a few strategic changes from the previous version.
Does it work? You bet!
var tokens = [
{ type: 'num', value: 2 },
{ type: 'sym', value: '*' },
{ type: 'num', value: 3 },
{ type: 'sym', value: '+' },
{ type: 'num', value: 4 },
{ type: 'sym', value: '/' },
{ type: 'num', value: 5 },
];
PrecedenceShuntingYard(tokens);
=> {
type: 'add',
parms: [{
type: 'mul',
parms: [{
type: 'val',
value: 2
}, {
type: 'val',
value: 3
}
]
}, {
type: 'div',
parms: [{
type: 'val',
value: 4
}, {
type: 'val',
value: 5
}
]
}
]
}
What sort of black magic is this?!
Let’s ignore NextToken and ApplyBinOp – they haven’t changed.
ApplyLeftFirst
The ApplyLeftFirst function is fairly simple – it takes two symbols, and returns true if the
left symbol should be applied first. Otherwise, the right symbol should be applied first.
This decision is made using precedence information. The + and - have a precedence of 0, and
* and / have a precedence of 1.
The comparison at the end is important:
return sym_to_prec[leftSymbol] >= sym_to_prec[rightSymbol];
Why was >= used here? Why not >?
Think about what the right answer is. If the two precedence levels are the same, then we should favor the left operator, because all the operators we support are left-associative.
Therefore, we should return true, since we want the left operator applied first.
opStack and valStack
Notice that our variables lastOp and lastValue have been transformed into stacks – now named
opStack and valStack.
Also notice that throughout the function, the top of the stacks are at index 0. This doesn’t
really matter – it’s just less typing. But it means that we use unshift and shift (instead of
push and pop).
Another important piece to notice is that we don’t really need the nextValue variable. We
immediately unshift the value on top of the value stack, and just use the value stack in the rest
of the algorithm.
ApplyTopOp
Our first piece of magic comes from transforming ApplyLastOp to ApplyTopOp.
Instead of always applying the last operator, now the function applies the operator on top of the operator stack.
More importantly: it applies the operator by shifting off the values from the value stack, and unshifts the result back onto the value stack.
That means that every time ApplyTopOp is called, one less operator exists on the operator stack,
and one less value exists on the value stack (two values unshifted, one value shifted).
This is important to realize because it can be confusing at first to wonder how the stacks always empty correctly, with no operators on the operator stack, and always one value on the value stack.
This is accomplished because one value is always added at the top of the loop
via valStack.unshift(nextValue). If there is an operator, then it gets pushed on the operator
stack via opStack.unshift(tok.value), and another value is unshifted immediately afterwards (due
to the loop).
Since ApplyTopOp always removes one element from each stack, we are guaranteed that there
is always one extra value on top of the value stack at the end of the function.
The Heart
Lastly, we come to the heart, in the middle of the loop:
// check to see if we have previous operations to apply
while (opStack.length > 0 && ApplyLeftFirst(opStack[0], tok.value))
ApplyTopOp();
What is going on here?!
This is where it helps to view the problem as a competition between two operators. Who wins? Who gets to apply first?
If the left operator wins, then we execute ApplyTopOp(), which applies the operator on the top of
the stack (the left operator).
Since ApplyTopOp() will remove an operator from the operator stack, when the condition executes
again, we are comparing the next left operator against the current operator. Which one wins?
As long as the left operator wins, it is applied via ApplyTopOp().
Then, either we run out of left operators (detected because opStack.length will be 0), or the
right operator wins (detected via ApplyLeftFirst(...) returning false).
In that case, we are back to our base case with our sample code from Part 1. We need to delay application of the right operator, because there might be operators further to the right that take precedence.
In order to delay application of the operator, we save it for later. Previously we did that using
the lastOp variable. This time, we have a stack. Therefore, we do:
opStack.unshift(tok.value);
When we loop around, the previously unshifted operator is now the left operator that is compared to things to its right.
Cleanup
Lastly, if we run out of tokens, then the main loop will exit. At that point, we need to apply any operators that were deferred until later.
// apply any left over operators
while (opStack.length > 0)
ApplyTopOp();
There are no right operators to compete for the value, so it’s safe to apply the remaining operators on the operator stack.
And if you’ve been following along, then you know at this point, we will have exactly ONE value on the value stack. We return this final value as our completely built AST:
// all done, so return the top of the tree
return valStack[0];
Fantastic, isn’t it?
Better News
This is really thrilling. By adding the two stacks, and making decisions about which operators to apply at any moment, we are really starting to feel the power of the Shunting Yard algorithm.
As a matter of fact, this algorithm is completely valid for binary operators, and will remain unchanged for the rest of the series.
But we’re not done. We are missing some serious features. Parenthesis don’t work, prefix and postfix operators are missing, and we have a long way to go to unlock the mystery of the ternary operator. I’ll see you next time!